Twilio + AWS Lamba + Rev = Easy call recording!
I have been doing a bunch of user interviews at work. It’s been difficult to get our users in front of a computer, or to get them to install video conferencing software, so I’ve been calling them on the telephone. I find that taking notes while I interview people kills my flow, and I’m really not very good at it, so I needed a way to easily record these phone calls, and then get them transcribed.
There are a bunch of solutions out there, but they all seem to rely on a third party app that make a VoIP call. This presented me with three problems:
- Our spotty office wifi caused drop outs – and when it did work, the quality was terrible (thanks Australia!);
- The incoming number was a either blocked or some weird overseas number, which users promptly ignored
- Automatic transcription of phone calls is woeful – because of the low bandwidth, the audio signal isn’t great, and computers do a really bad job at translating it to text.
When I was last at JSConf, I got chatting to Phil Nash who is a developer evangelist at Twilio. I asked him whether I could setup a number that I could call, have me enter a number, dial that number and record the call. He said it should be easy.
Challenge accepted.
Spoiler alert: It is.
Note: This code and deployment process isn’t actually the one I used at work. We use Golang, which is way more lines of code, and has way more boiler plate – and I needed to write an abstraction around TwiML – so I chose to rewrite it in Python here for simplicity’s sake. We also use CloudFormation to create Lambdas and API gateways, and have a CI build pipeline to deploy them, which isn’t conducive to a pithy blog post. Does this process work? Yes. Would you use it in real world in a production environment? Up to you. 🤷♀️
An overview
At a high level, this is what happens when you dial the number and request an outgoing call:
- Twilio answers your call
- Twilio makes a request to an Amazon Lambda via an API Gateway, which returns some TwiML instructing Twilio’s voice engine to ask you to enter a phone number.
- It waits for you to enter the phone number followed by the hash key
- When it detected the hash key, it makes another request to the lambda, this time with the number you entered. The lambda returns an instruction to dial the number (after some normalisation – more on this later), join the calls, and to record both sides of the conversation.
After this happens, you can log in to the Twilio console, download the MP3, and upload that to Rev.com where real-life humans transcribe the conversation.
The code
from twilio.twiml.voice_response import VoiceResponse, Say, Gather, Dial
from urllib.parse import parse_qs
LANGUAGE="en-AU"
AUTHORISED_NUMBERS = ['ADD YOUR PHONE NUMBER HERE IN INTERNATIONAL FORMAT ie +61400000000']
def authorized_number(number):
return number in AUTHORISED_NUMBERS
def say(words):
return Say(words, voice="alice", language=LANGUAGE)
def get_outgoing_number(request):
response = VoiceResponse()
action = "/" + request['requestContext']['stage'] + "/ivr"
words = say("Please dial the number you would like to call, followed by the hash key.")
gather = Gather(action=action)
gather.append(words)
response.append(gather)
return response
def add_country_code(number):
if number[0] == "+":
return number
elif number[0] == "0":
return "+61" + number[1:]
elif number[0:2] == "13":
return "+61" + number
elif number[0:2] == "1800":
return "+61" + number
def hangup():
response = VoiceResponse()
response.hangup()
return response
def handle_ivr_input(params):
to = params['Digits'][0]
dial = Dial(add_country_code(to), record="record-from-answer-dual", caller_id=params['Caller'])
response = VoiceResponse()
response.append(say("Calling."))
response.append(dial)
return response
def handler(request, context):
path = request['path']
params = parse_qs(request['body'])
response = ""
if path == "/incoming":
if authorized_number(params["Caller"][0]):
response = get_outgoing_number(request)
else:
response = hangup()
elif path == "/ivr":
response = handle_ivr_input(params)
else:
return {
'body': "Action not defined",
'statusCode': 404,
'isBase64Encoded': False,
'headers': { 'context_type': 'text/plain' }
}
return {
'body': str(response),
'statusCode': 200,
'isBase64Encoded': False,
'headers': { 'content_type': 'text/xml' }
}
Code is also on GitHub.
I’m in Australia, so there is a little bit of localization happing here: I set the voice of Alice (the most human sounding robot that Twilio has) to Australian, and I insert the Australian country code if it is not already set. Twilio doesn’t do this automatically, and it’s a pain to replace the first 0 with a +61 for every call.
When the call is made, the caller ID is set to the number you called from, so the call looks like it came from you. You need to authorise Twilio to do that.
I’ve included a hard-coded allow-list (AUTHORISED_NUMBERS) of phone numbers who can make outgoing phone calls. If a number that is not on the list tries to call the number, they just get hung up on. You wouldn’t want someone accidentally stumbling across the number and racking up phone bills. I guess at least you would have recordings as evidence…
Note: the code doesn’t know about area codes, so if you are calling land lines (Wikipedia entry if you are under 30 and don’t know what they are) you will always need to include your area code.
Cool. So what do you do with this code? It needs packaging and uploading to Amazon.
Packaging the script
(Want to skip this bit? Here is the ZIP – you can edit it in the Lambda console once you upload)
You will need Python 3.6 for this. Instructions for OSX, Linux and Windows. Good Luck.
git clone git https://github.com/madpilot/twilio-call-recorder
cd twilio-call-recorder
pip install twilio -t ./
find . | grep -E "(__pycache__|\.pyc|\.pyo$)" | xargs rm -rf
zip -r lambda.zip *
Creating the Lambda
- Log in to your AWS account, and go to https://console.aws.amazon.com/lambda/home
- Click Create function
- Then Author from scratch
- Name your lambda: twilioCallRecorder
- Select Python 3.6 as the runtime
- Select the Create new role from template(s) option
- Name the role: twilioCallRecorderRole
- Click Create Function
Your screen should look similar to this:
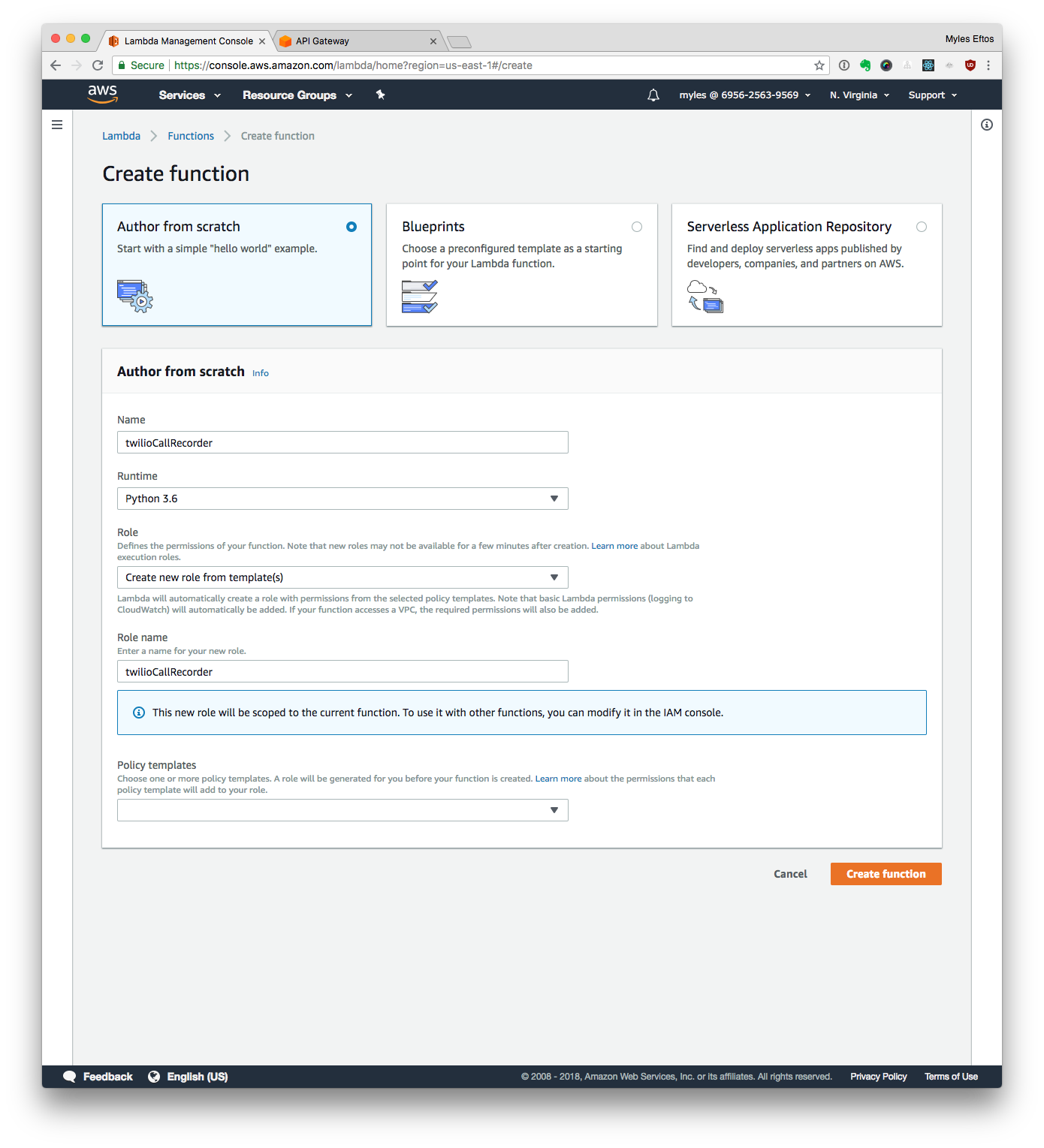
Important! Don’t Add a trigger from this screen! We need to set the API gateway in a non-standard way, and it just means you’ll have to delete the one this page sets up.
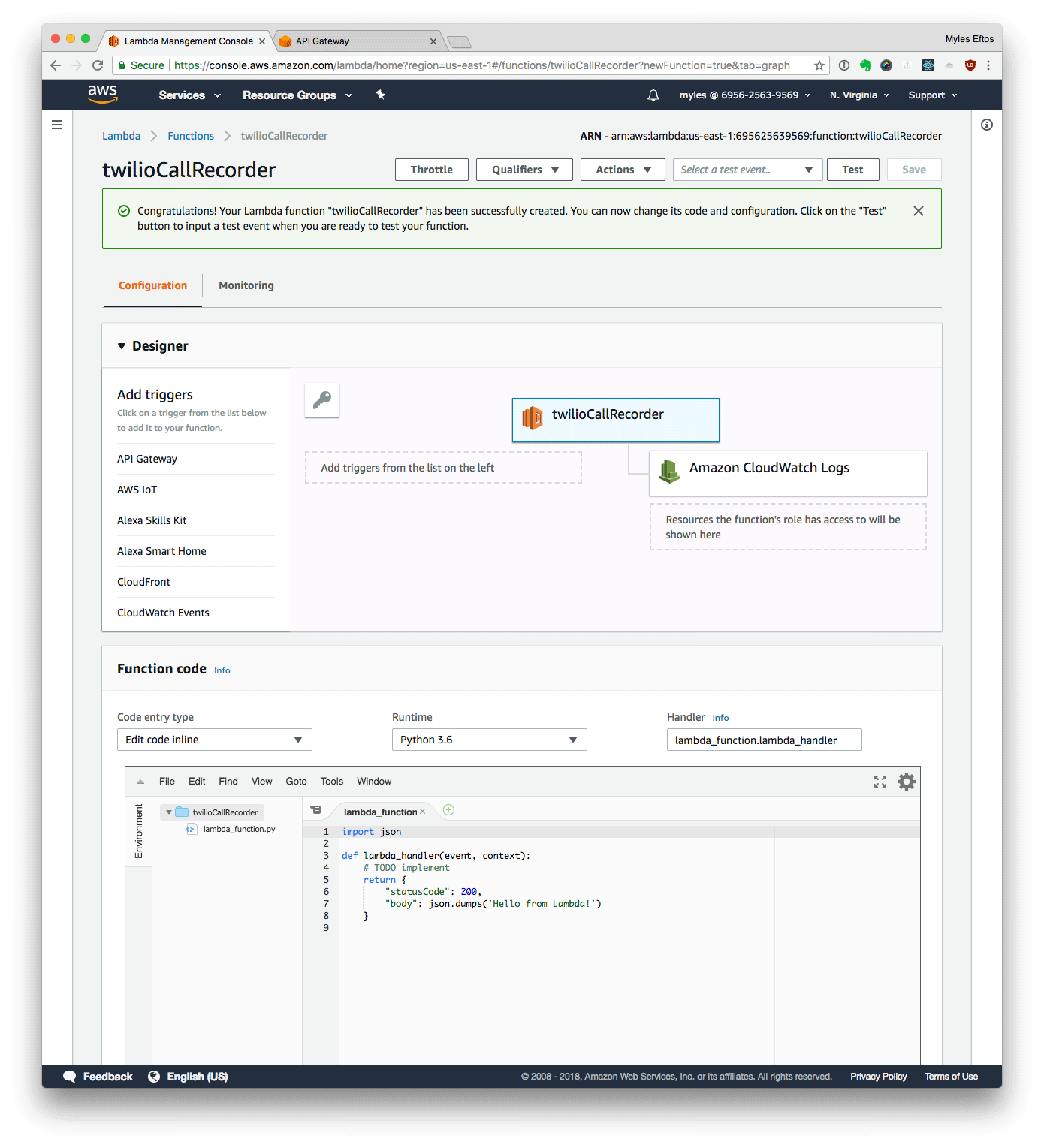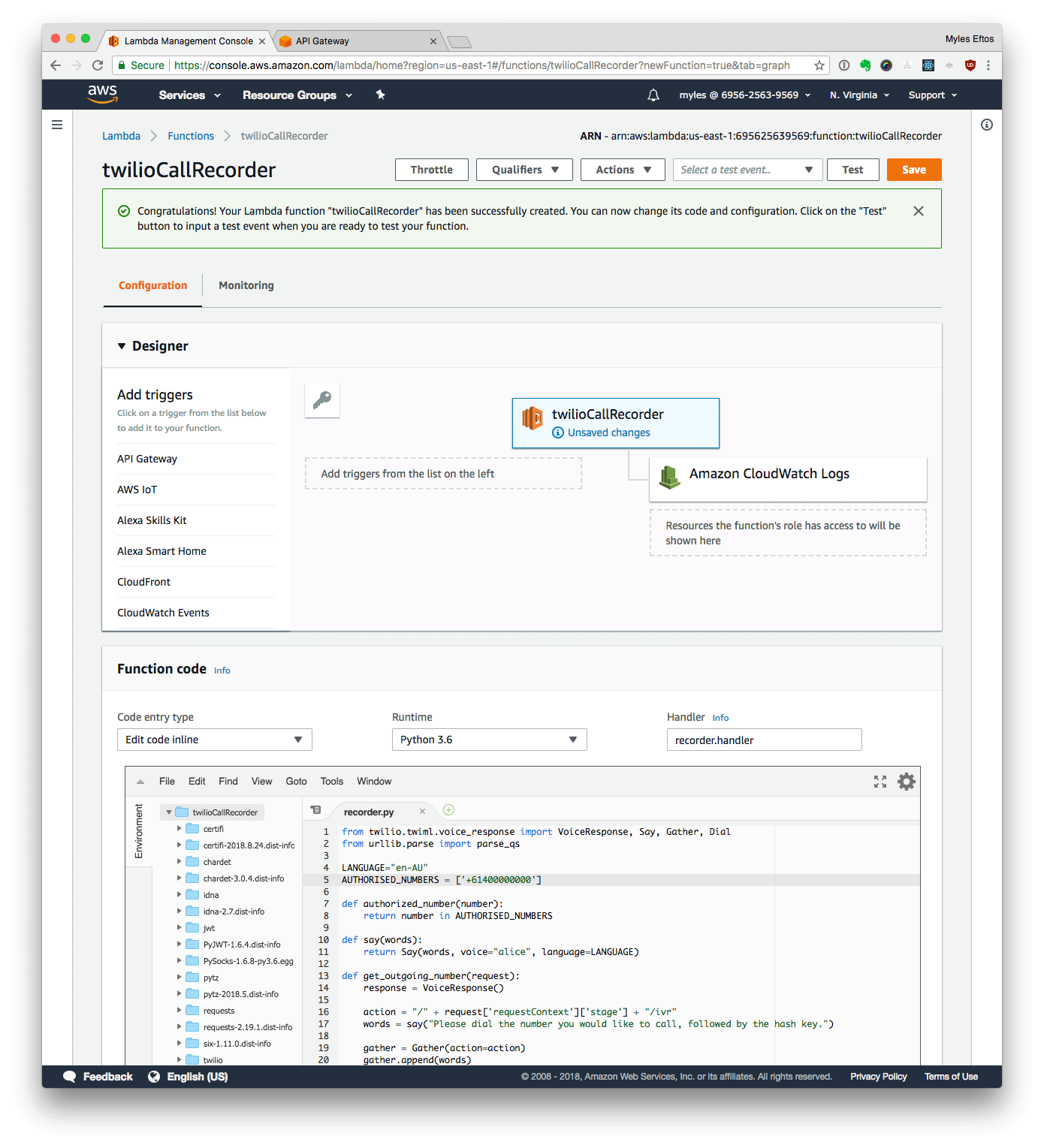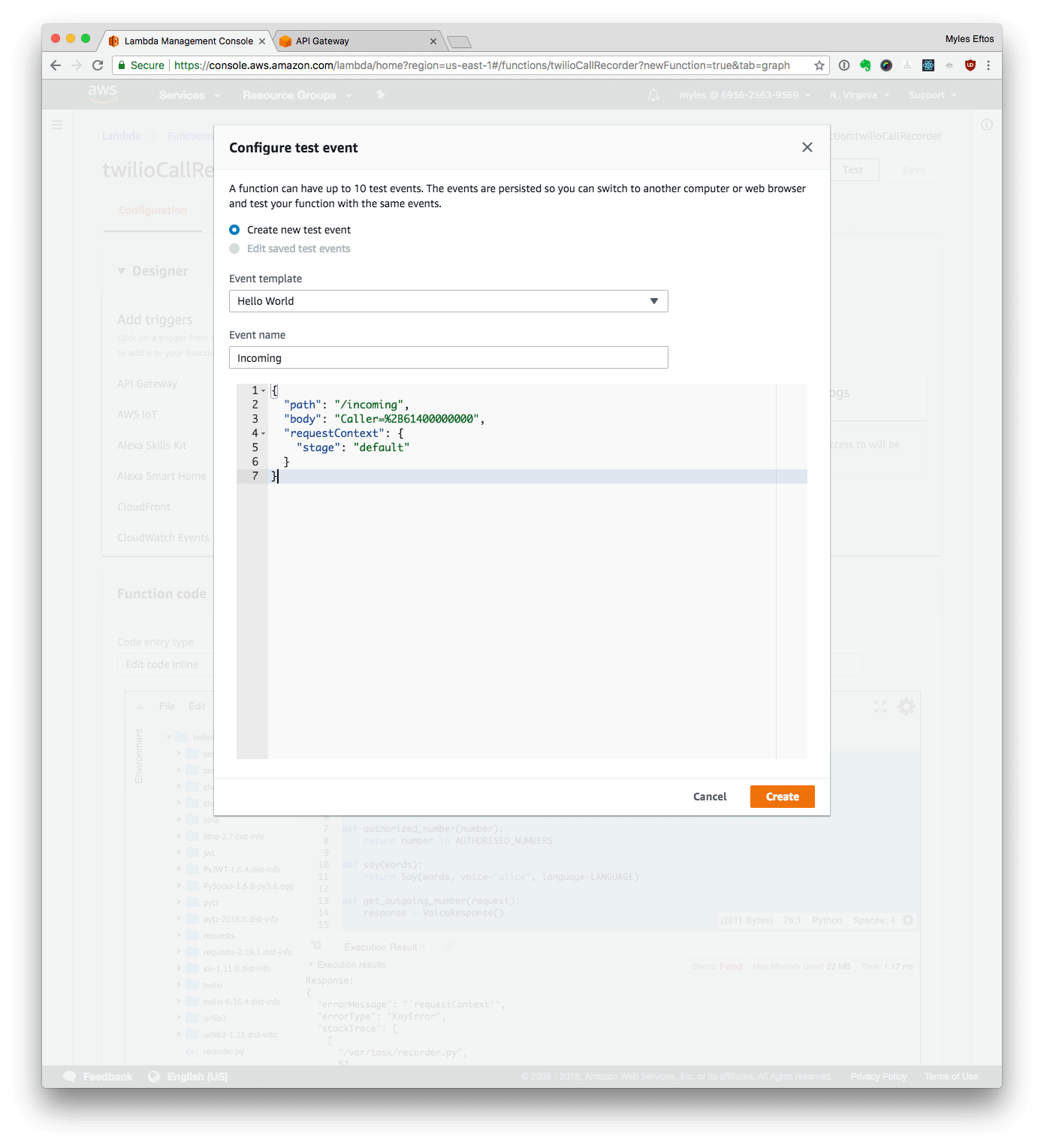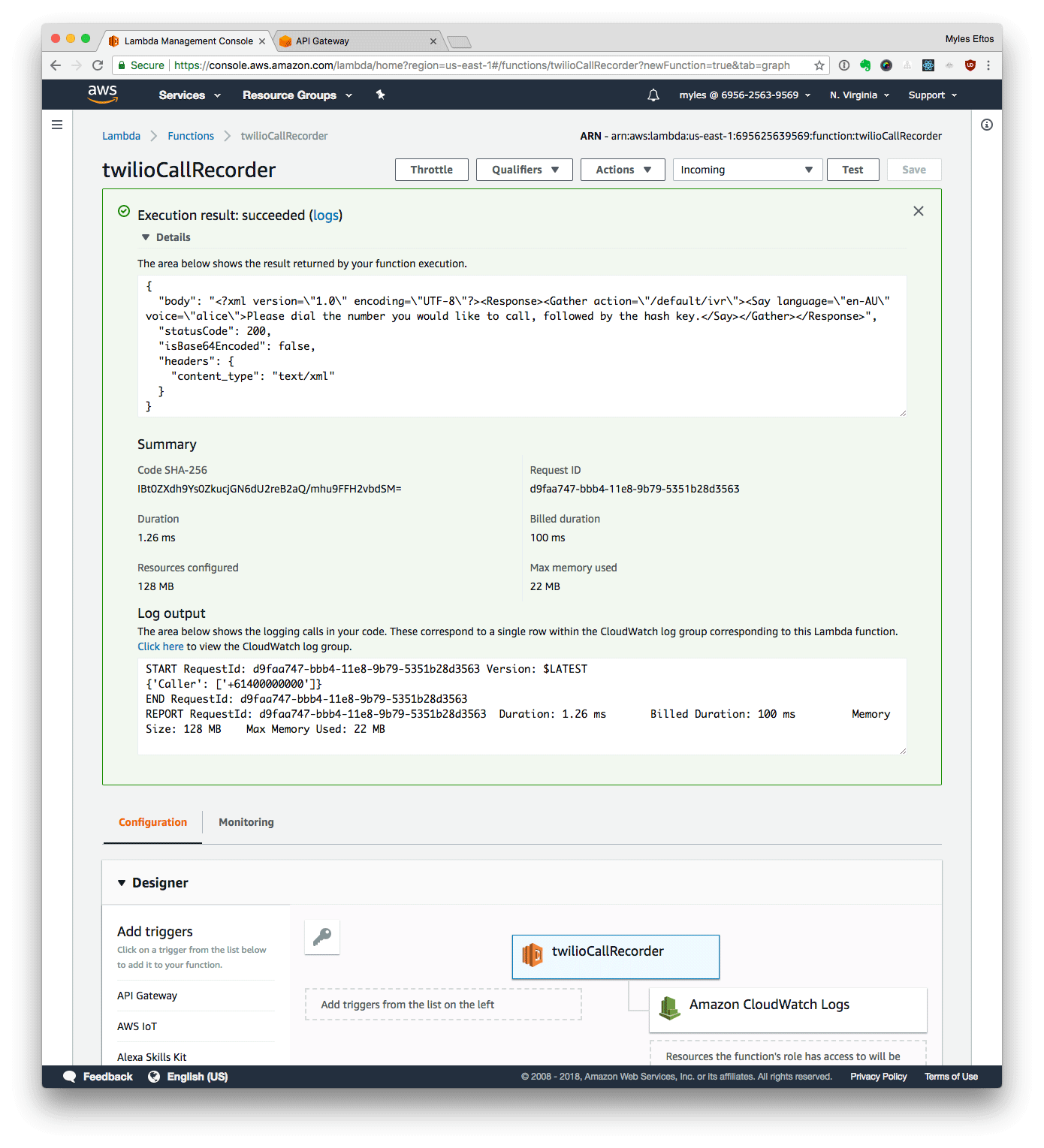
Uploading the Code
- Upload ZIP File
- Set the handler to recorder.handler
- Click Save
- In the code editor, Add all the phone numbers who can make outgoing calls to the AUTHORISED_NUMBERS list (include +61 at the beginning)
- Click Test
- Set the event name to Incoming”
Set the payload to
{
"path": "/incoming",
"body": "Caller=%2B61400000000",
"requestContext": {
"stage": "default"
}
}
- Click Create
- Click Test
Setting up the Web API Gateway
- Click Get Started
- Click New API
- Name the API Twilio Call Recorder
- Click Create API
- From the Actions menu, select Create Resource
- Check the Configure as Proxy Resource option
- Click Create Resource
- Start typing the name you gave the Lambda (twilioCallRecorder) – it should suggest the full name
- Click Save
- Click Ok
- Click Test
- Select Post in the Method drop down
- Select /incoming as path
- Set RequestBody to
Caller=%2B61400000000
replacing 61400000000 with one of the numbers in your allow list
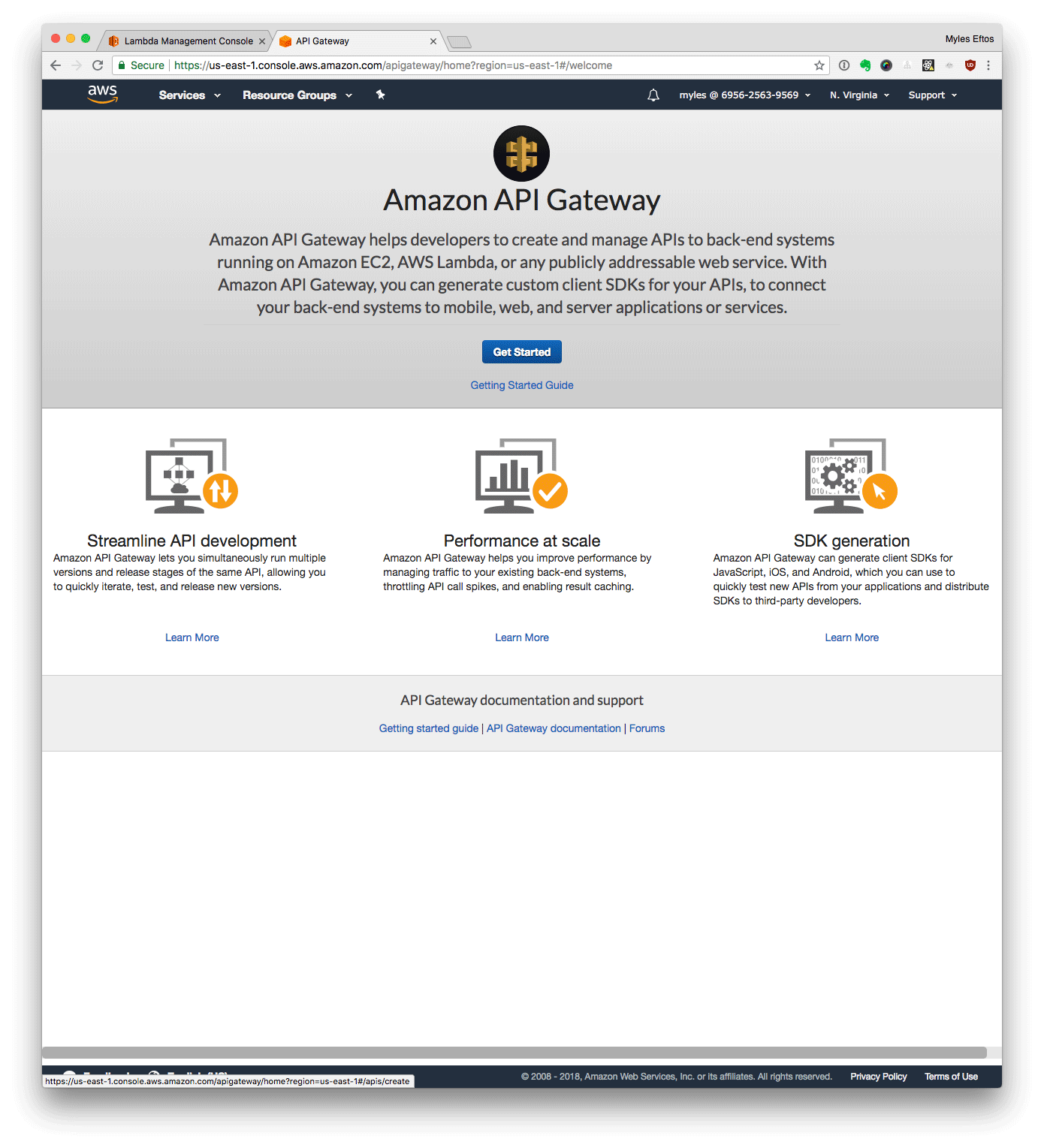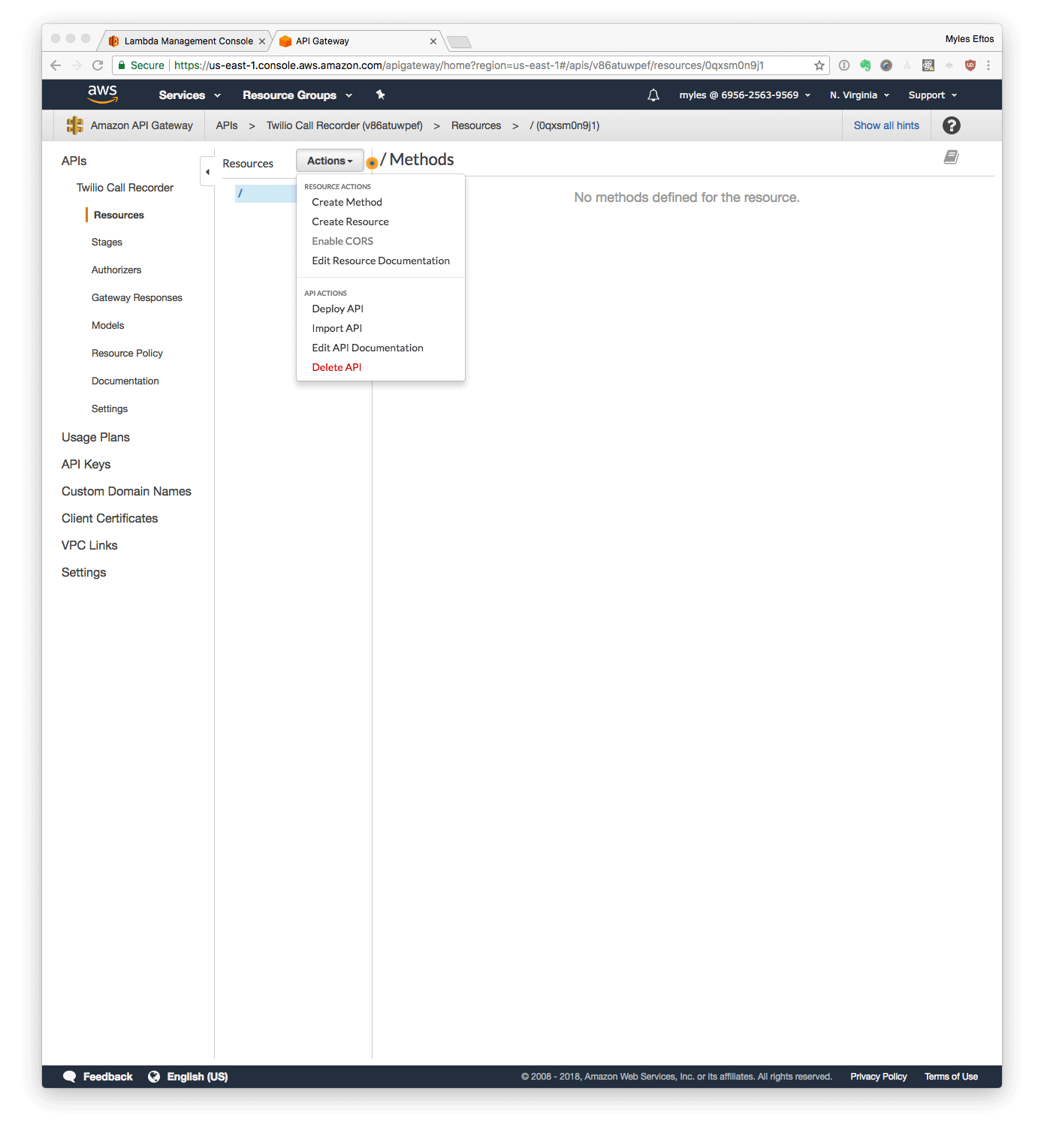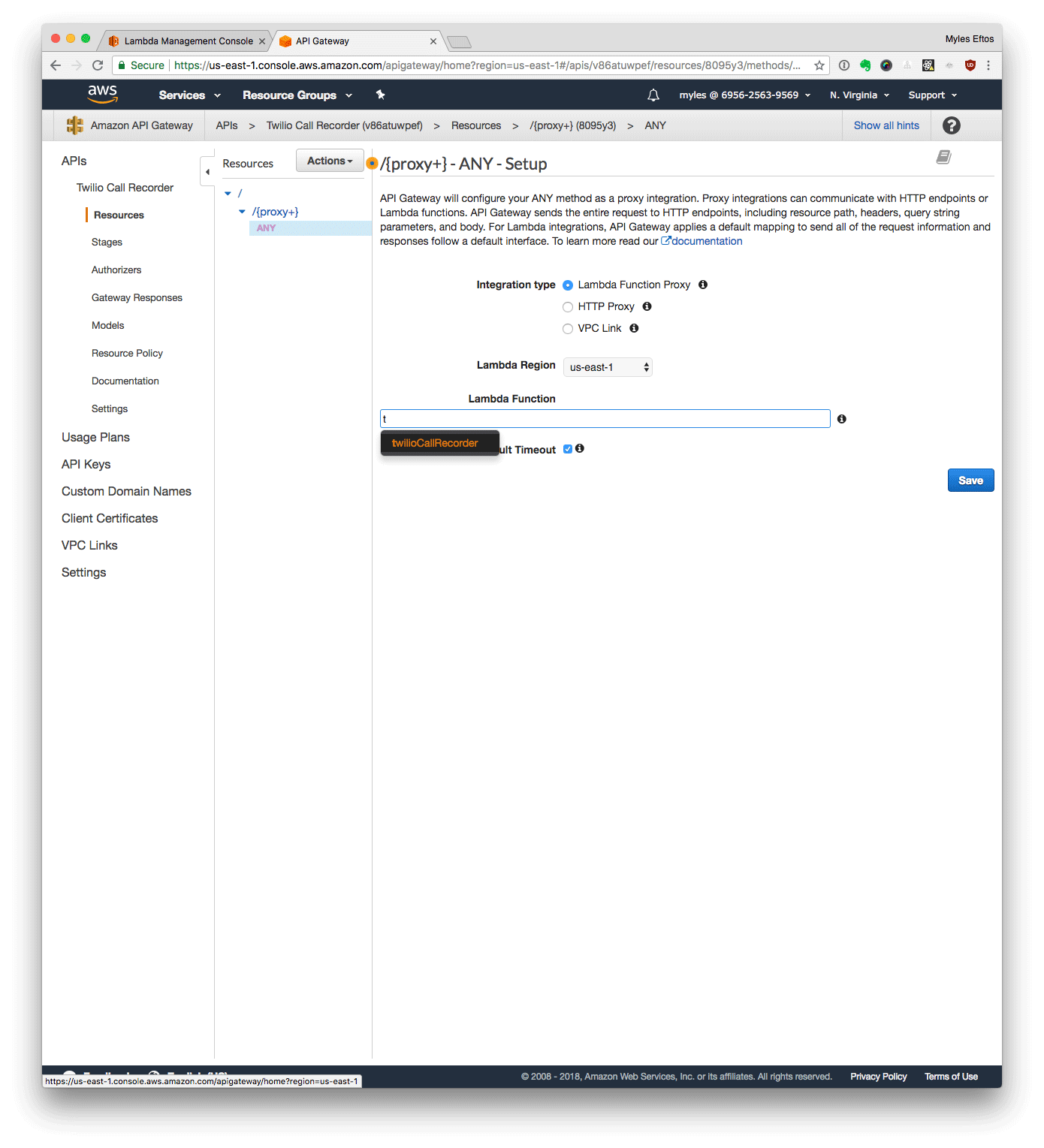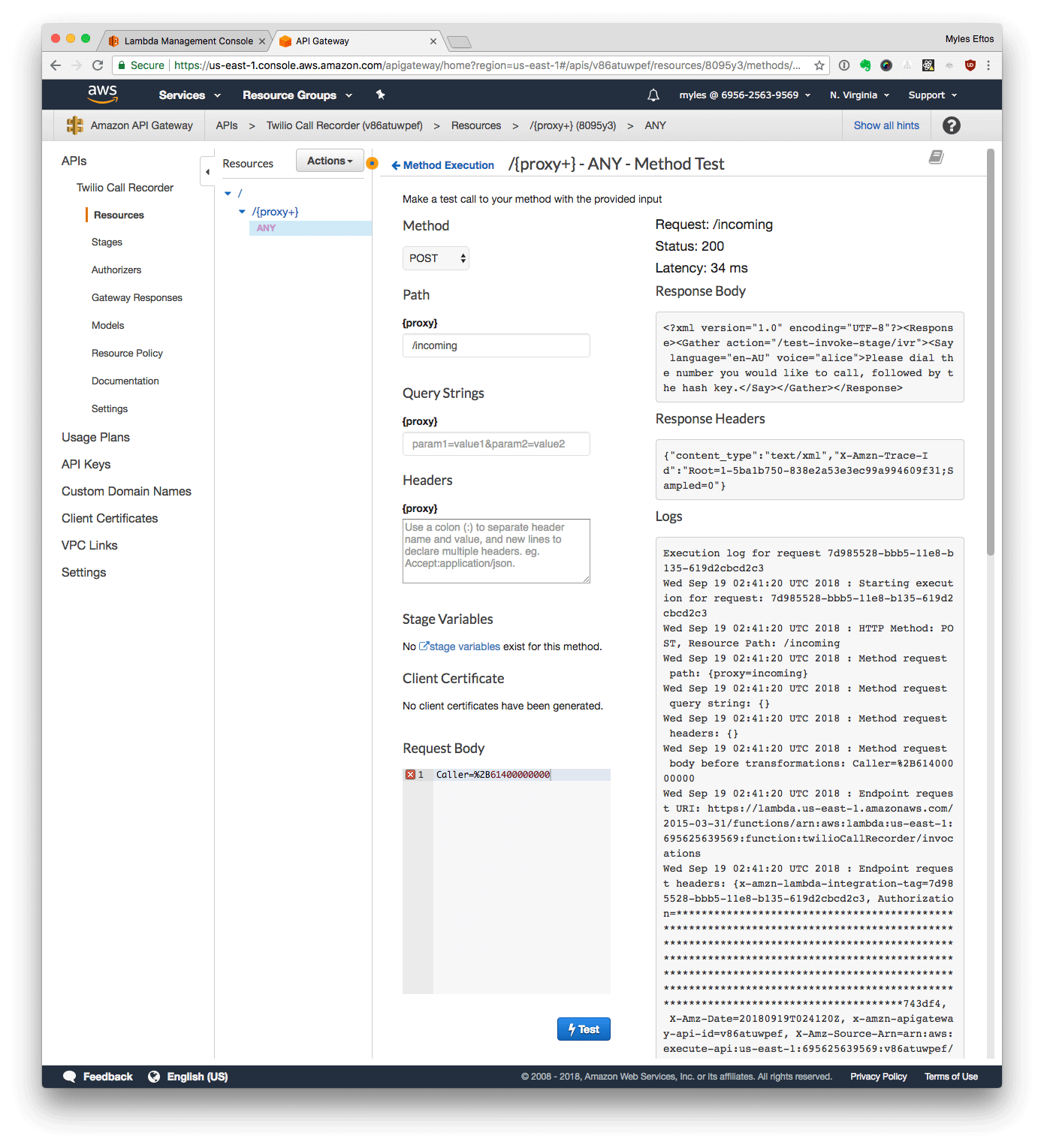
- Click Test
If that all worked, you should see a success message.
Deploy the API Gateway
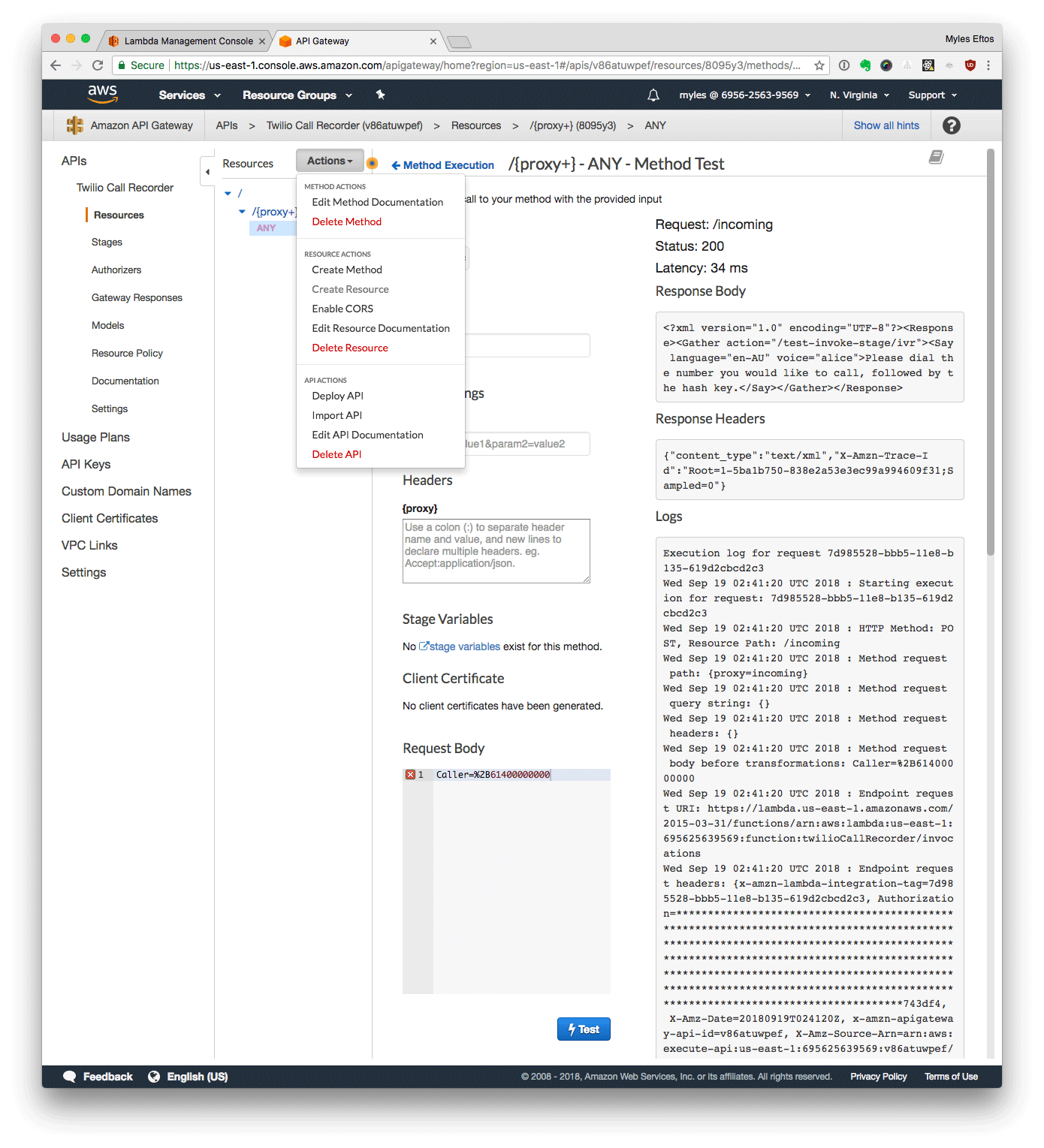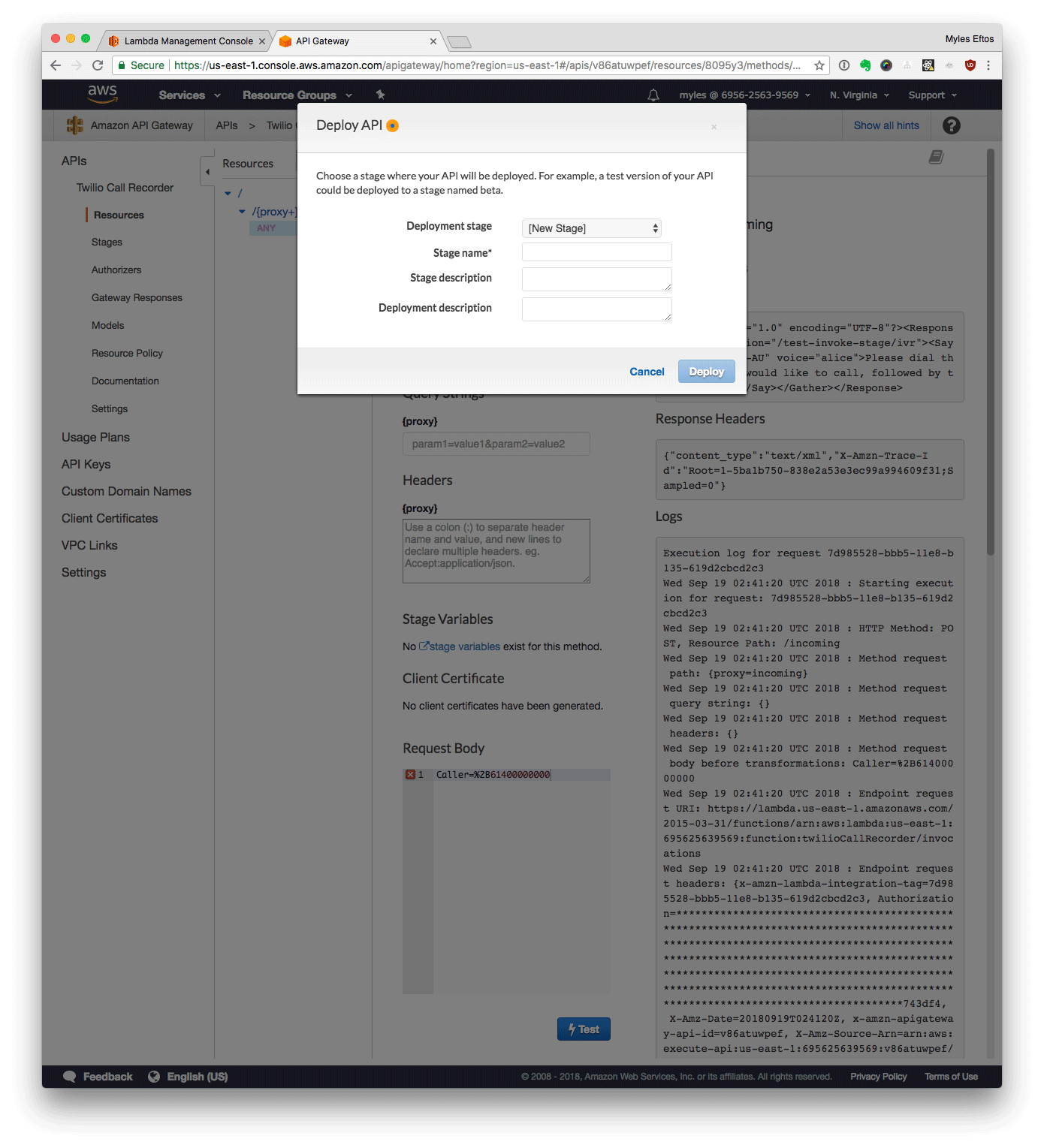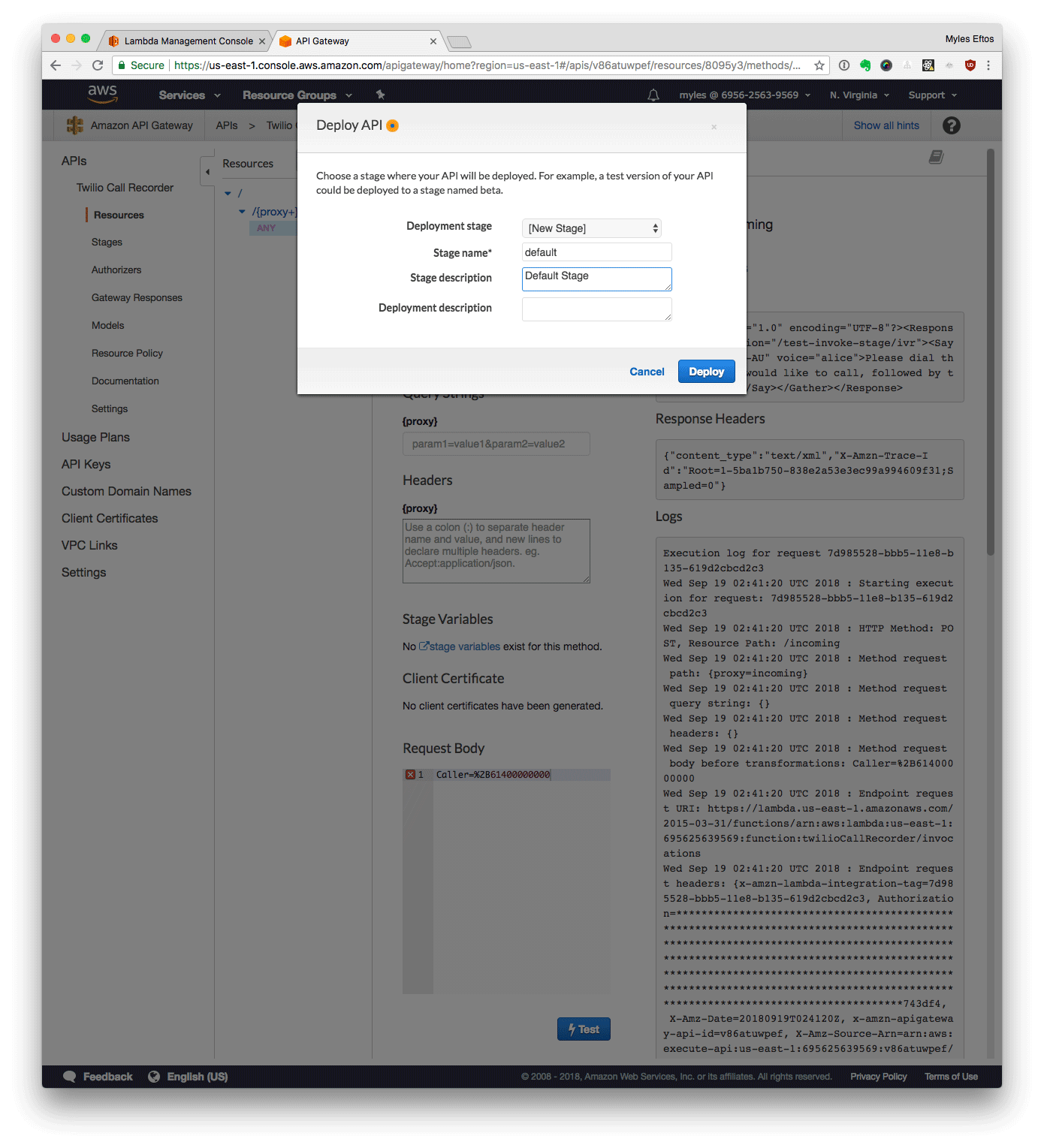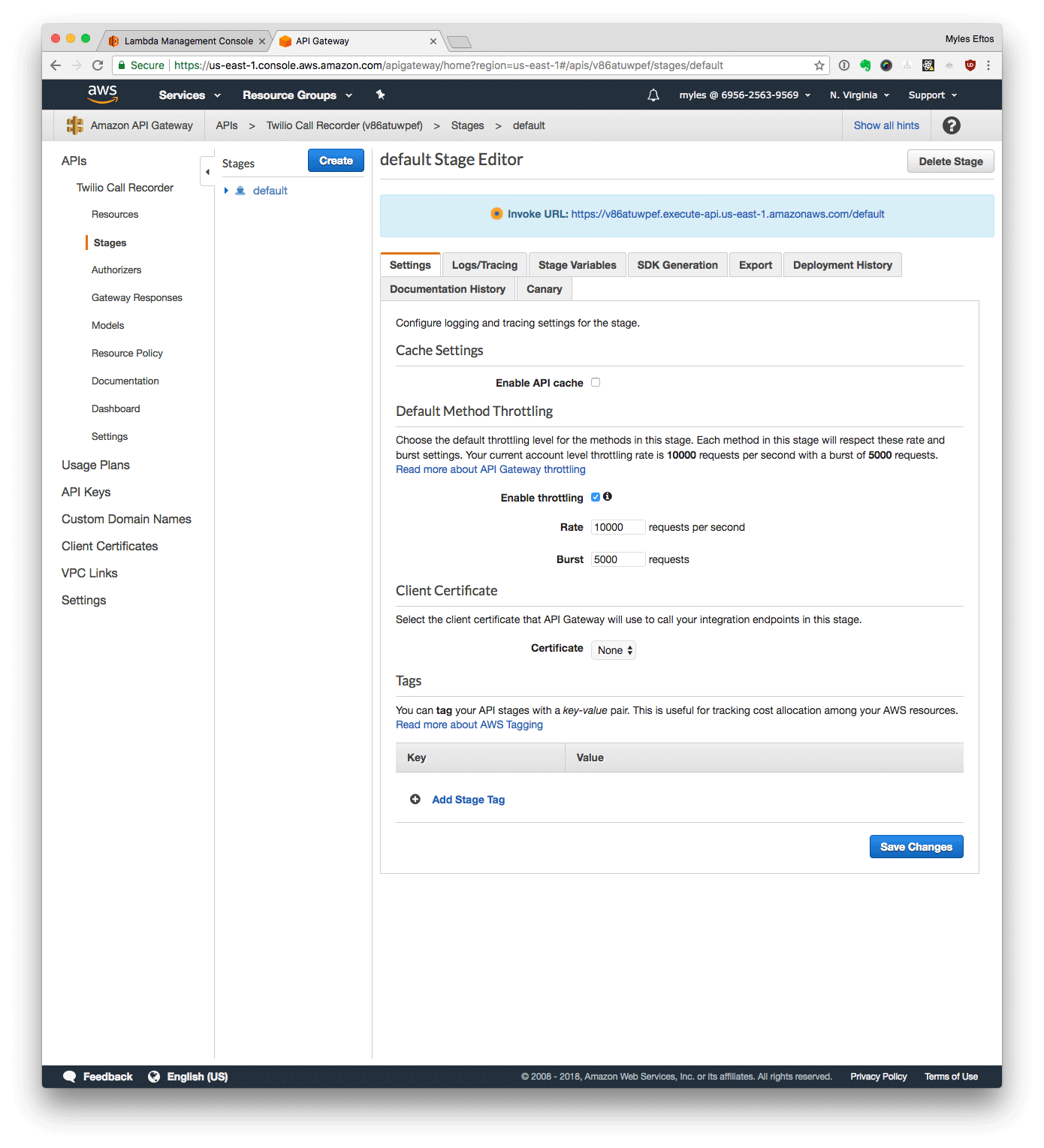
- From the Actions menu, select Deploy API
- Enter Default as the name
- Click Deploy
Copy the invoke URL. In a terminal (if you are on a Mac):
curl `pbpaste`/incoming -d "Caller=%2B61400000000"

Congratulations! You have setup the API Gateway and Lambda correctly!
Setup Twilio
See the documentation around webhooks on the Twilio website – paste in the URL from the API gateway, and you are good to go.
Making a call
The part you have been waiting for! Pick up your phone, and dial the incoming number you setup at Twilio. If all is well, you should hear a lovely woman’s voice asking you the number you wish to dial. Enter the number, and hit the hash key. After a moment, the call will be connected!
Once you hang up, you can log in to the Twilio console, browse to the Programmable Voice section and click the Call log. You should see the call you made. Click on it and you will be able to download a WAV or MP3 version of the recording.
Now, you just need to download it (I chose the MP3, because it will be faster), and upload it to Rev.com. After a couple of hours, you will have a high quality transcription of your conversation. It’s really very easy!